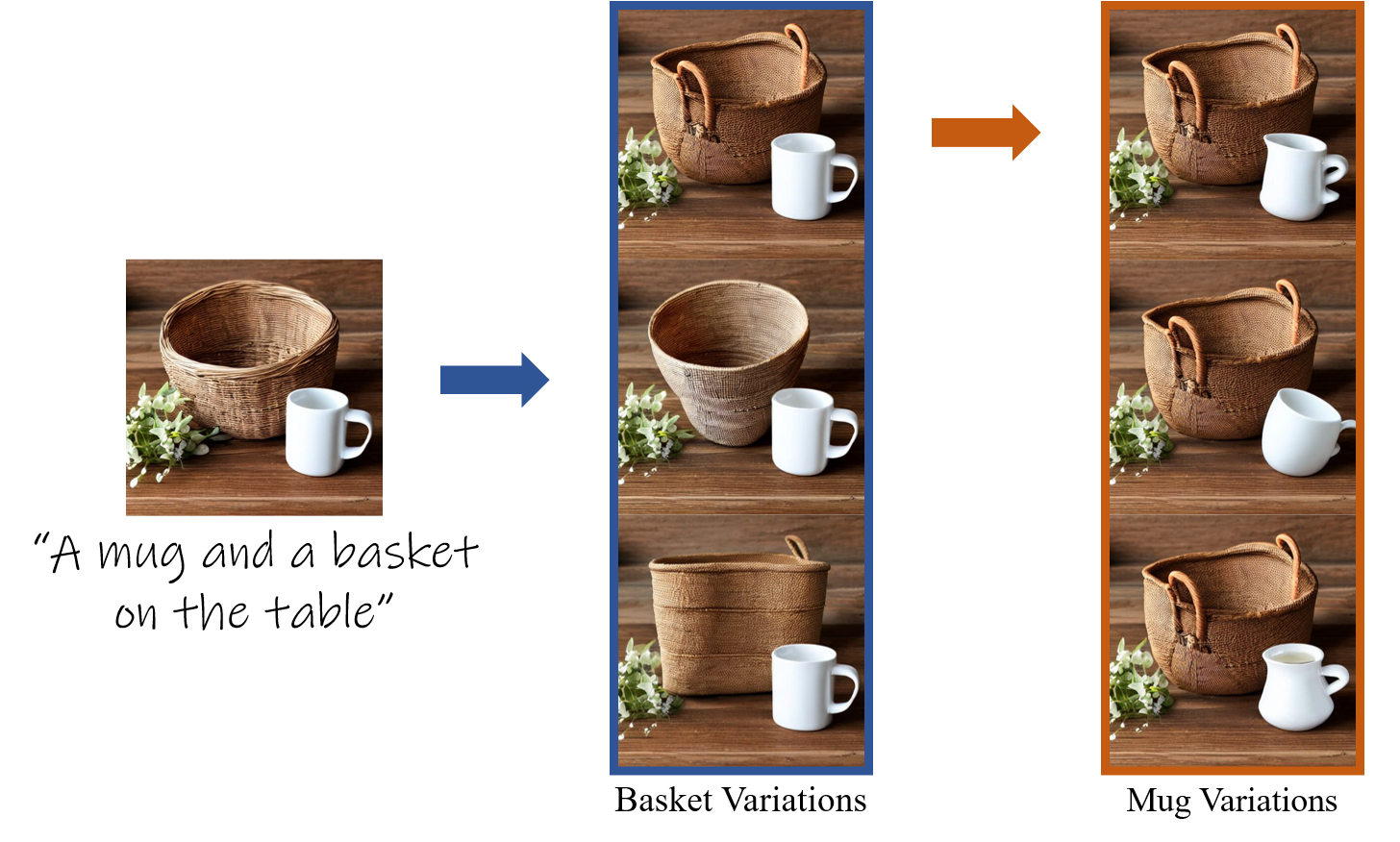






Text-to-image models give rise to workflows which often begin with an exploration step, where users sift through a large collection of generated images. The global nature of the text-to-image generation process prevents users from narrowing their exploration to a particular object in the image. In this paper, we present a technique to generate a collection of images that depicts variations in the shape of a specific object, enabling an object-level shape exploration process. Creating plausible variations is challenging as it requires control over the shape of the generated object while respecting its semantics. A particular challenge when generating object variations is accurately localizing the manipulation applied over the object's shape. We introduce a prompt-mixing technique that switches between prompts along the denoising process to attain a variety of shape choices. To localize the image-space operation, we present two techniques that use the self-attention layers in conjunction with the cross-attention layers. Moreover, we show that these localization techniques are general and effective beyond the scope of generating object variations. Extensive results and comparisons demonstrate the effectiveness of our method in generating object variations, and the competence of our localization techniques.
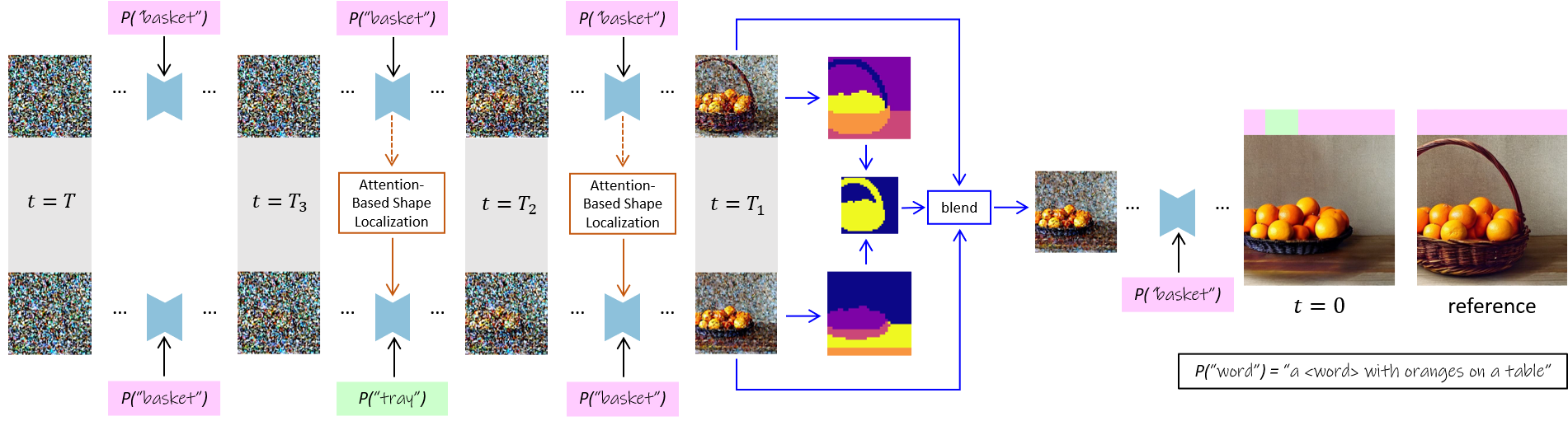
Given a reference image, and its corresponding denoising process, our full pipeline consists of three main building blocks. We perform Mix-and-Match in the timestamp intervals [T, T3], [T3, T2], [T2, 0] using the prompt P(w).
For example, during the intervals [T, T3], [T2, 0] we set w=''basket'', while during the interval [T3, T2] we set w=''tray''.
During the denoising process, we apply our attention-based shape localization technique to preserve other objects' structures (here, ''table''). We do so by selectively injecting the self-attention map from the reference denoising process. At t=T1, we apply controllable background preservation by segmenting the reference and the newly generated images, blend them, and proceed the denoising process.

Mix-and-Match is built on prompt-mixing. We observe that the denoising process roughly consists of three stages. In the first stage, the general configuration or layout is drafted. In the second stage, the shapes of the objects are formed. Finally, in the third stage, their fine visual details are generated.
In the above example, the images in the three leftmost columns were generated using the prompt ''Two w on the street'' where w is indicated over the bar under each image. The images in the two rightmost columns were generated using prompt-mixing. That is, we change w along the denoising process where the bar under each image indicates the w used in each stage.
For example, the upper rightmost image was generated in the following way. In the first denoising stage, we used w=''balls'', in the second stage we used w=''pyramids'', and in the last stage we used w=''fluffies''.
As can be seen, the layout is taken from the first stage, the object's shape is taken from the second stage, and the fine-visual details are taken from the third stage. In Mix-and-Match, to attain object shape variations we change the word corresponding to the object we aim to change only in the second stage. This allows us to preserve the layout of the original image, the fine-visual details of the original object, and to change its shape.
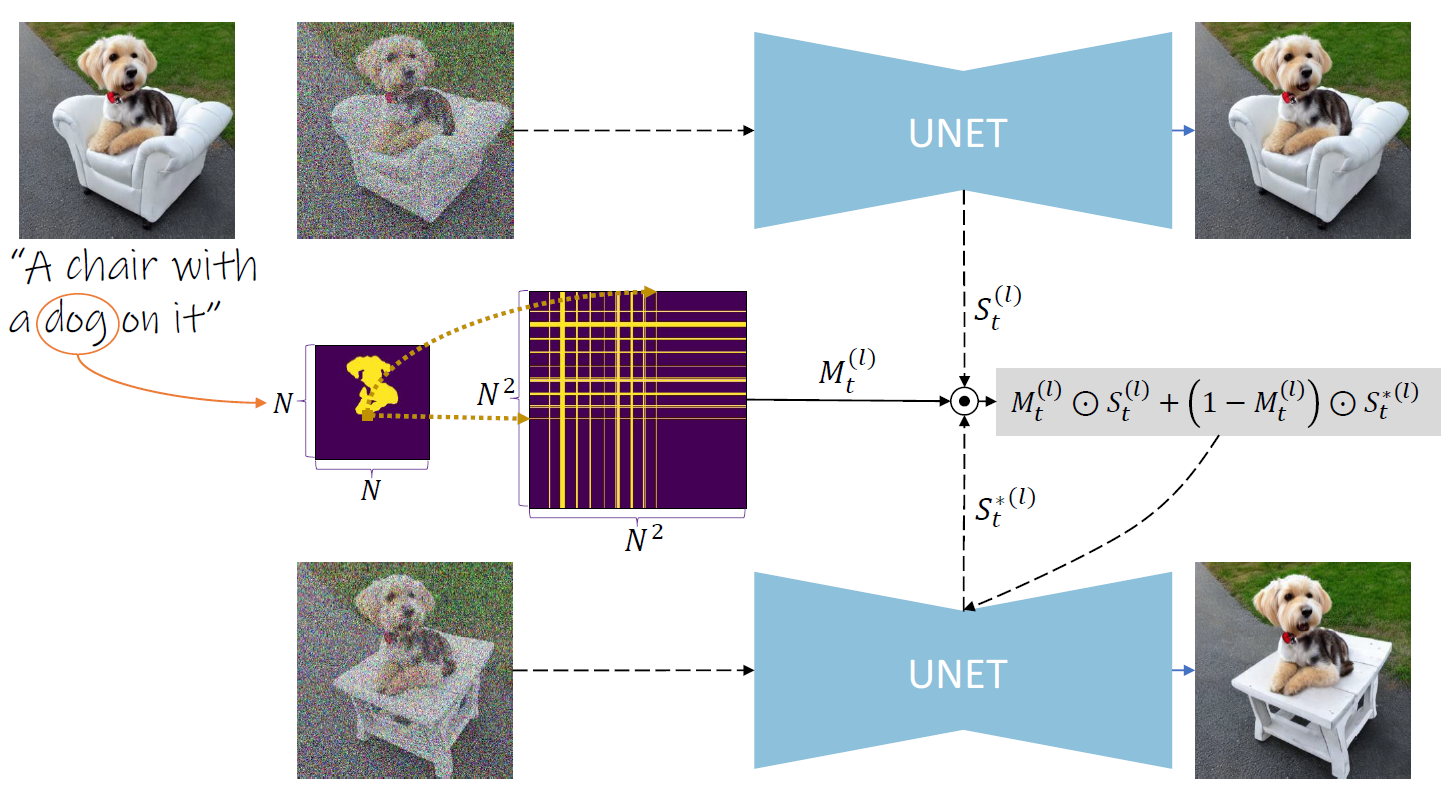
Our method changes the shape of a specific object, and preserves the other objects in the image. In the above example, we aim at changing the chair while preserving the dog. To preserve an object (e.g., a dog) in an image, we locate its pixels using a cross-attention map. A mask Mt(l) is created for the self-attention map St(l) by setting rows and columns to 1 (yellow) based on the object's pixels (see the orange pixel). Using this mask, we blend the original and generated image's self-attention maps and replace the self-attention map of the generated image with the resulting map.
We show that this method can be integrated with other text-guided image editing methods, to improve their localization. For example, we show results with prompt-to-prompt:

To preserve the appearance of the desired regions, at t=T1 we blend the original and the generated images, taking the changed regions (e.g., the object of interest) from the generated image and the unchanged regions (e.g., background) from the original image.
To this end, we segment the generated image by utilizing the self-attention map. Specifically, we reshape the N2xN2 self-attention map to be NxNxN2 and cluster the deep pixels whose dimension is N2. In the paper, we show that this approach is useful for additional editing methods. In the figure below we show a few segmentation results. The label for each segment was automatically extracted using the cross-attention maps.

@InProceedings{patashnik2023localizing,
author = {Patashnik, Or and Garibi, Daniel and Azuri, Idan and Averbuch-Elor, Hadar and Cohen-Or, Daniel},
title = {Localizing Object-level Shape Variations with Text-to-Image Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year = {2023}
}